Align multiple slices to reconstruct 3D
(Estimated time: ~2 min)
3D reconstruction is an important application for spatial alignment. In this case we use SLAT to rebuild 3D structure from multiple mouse E15.5 embryo Stereo-seq slices data (Chen. et al).
You need following files as input, you can download them from here:
count_E15.5_E1S1.MOSTA.h5ad: section 1 of mouse E15.5 embryo
count_E15.5_E1S2.MOSTA.h5ad: section 2 of mouse E15.5 embryo
count_E15.5_E1S3.MOSTA.h5ad: section 3 of mouse E15.5 embryo
count_E15.5_E1S4.MOSTA.h5ad: section 4 of mouse E15.5 embryo
[1]:
# uncomment this line if you want to use interactive plot (only works in Jupyter but not in VScode)
# %matplotlib ipympl
import time
from pathlib import Path
from operator import itemgetter
import scanpy as sc
import numpy as np
import pandas as pd
from joblib import Parallel, delayed
import scSLAT
from scSLAT.model import run_SLAT_multi
from scSLAT.viz import build_3D
[2]:
sc.set_figure_params(dpi=100, dpi_save=150)
[3]:
file_path = '../../data/stereo_seq/counts/E15.5' # Replace it with your file path
file_list = [file for file in Path(file_path).iterdir() if 'MOSTA' in str(file)]
file_list
[3]:
[PosixPath('../../data/stereo_seq/counts/E15.5/count_E15.5_E1S3.MOSTA.h5ad'),
PosixPath('../../data/stereo_seq/counts/E15.5/count_E15.5_E1S2.MOSTA.h5ad'),
PosixPath('../../data/stereo_seq/counts/E15.5/count_E15.5_E1S4.MOSTA.h5ad'),
PosixPath('../../data/stereo_seq/counts/E15.5/count_E15.5_E1S1.MOSTA.h5ad')]
For demonstration, we subsample 8000 cells from each dataset
[4]:
def load_sample(file):
adata = sc.read_h5ad(file)
# subsample 8000 cells
adata = sc.pp.subsample(adata, n_obs=8000, random_state=0, copy=True)
return adata
[5]:
adata1,adata2,adata3,adata4 = Parallel(n_jobs=len(file_list)+1)\
(delayed(load_sample)(file) for file in itemgetter(*[3,1,0,2])(file_list))
We visualize every dataset in 2D before alignment
[6]:
sc.pl.spatial(adata1, spot_size=5, color='annotation')
sc.pl.spatial(adata2, spot_size=5, color='annotation')
sc.pl.spatial(adata3, spot_size=5, color='annotation')
sc.pl.spatial(adata4, spot_size=5, color='annotation')
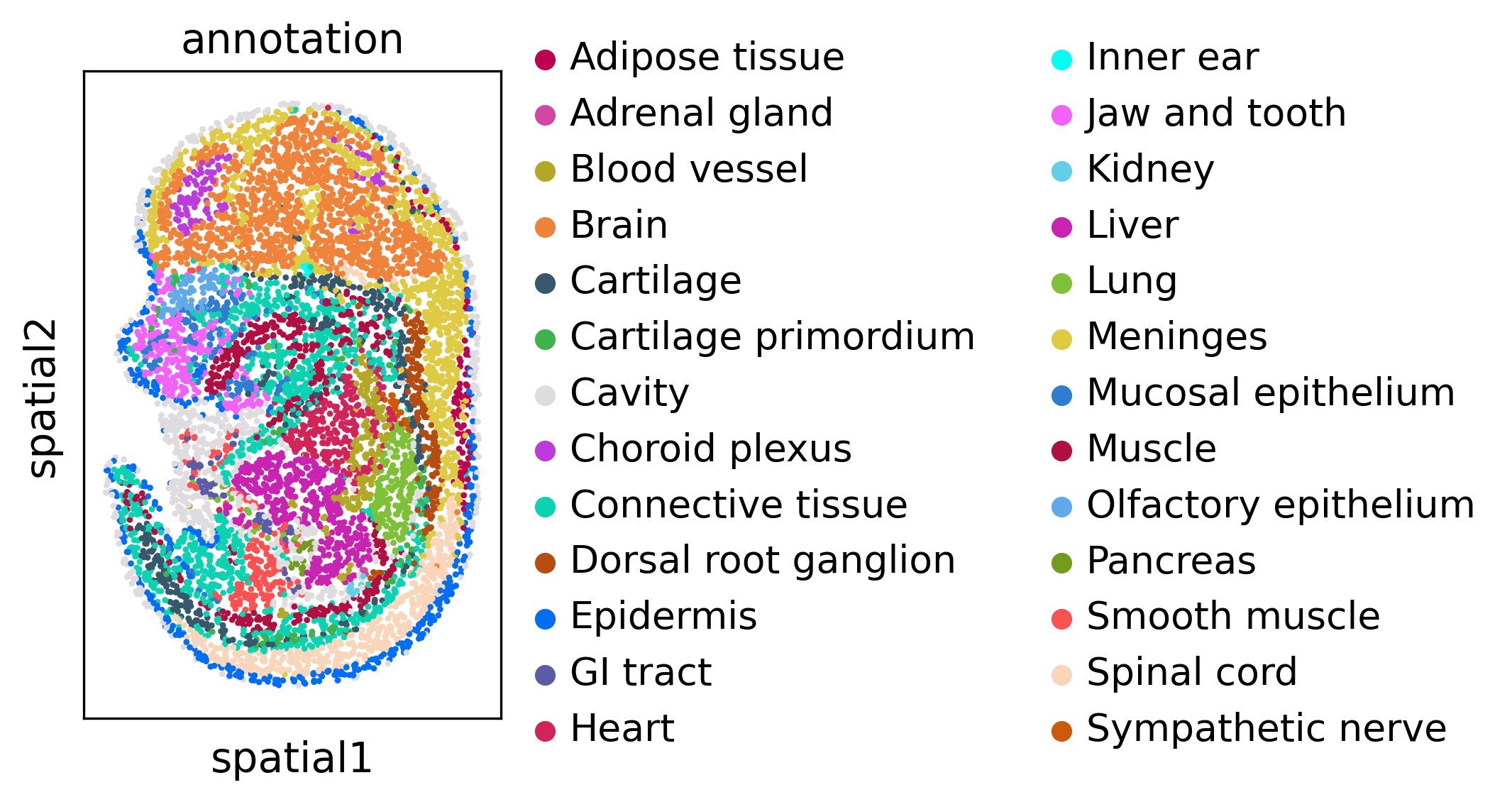
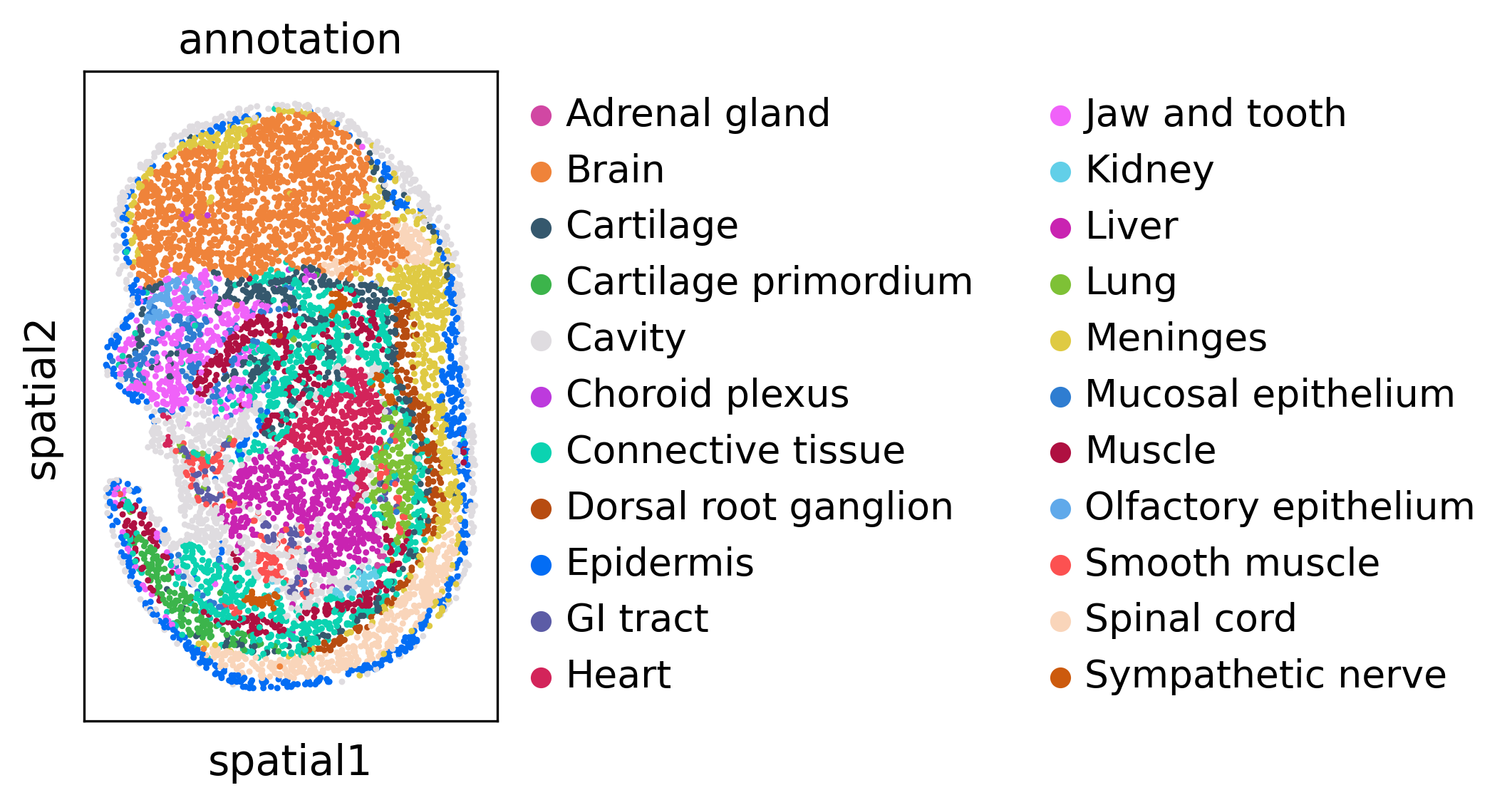
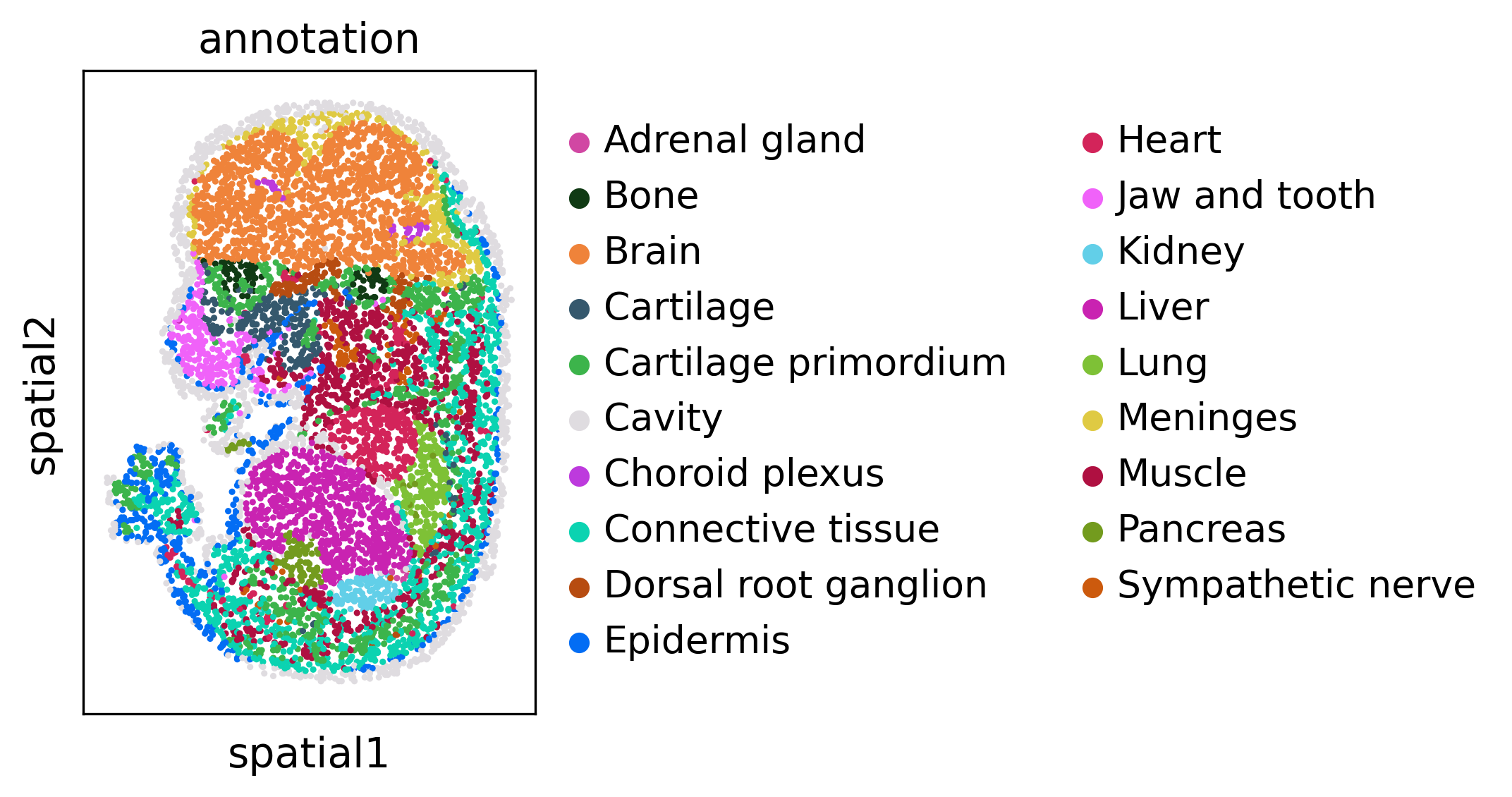
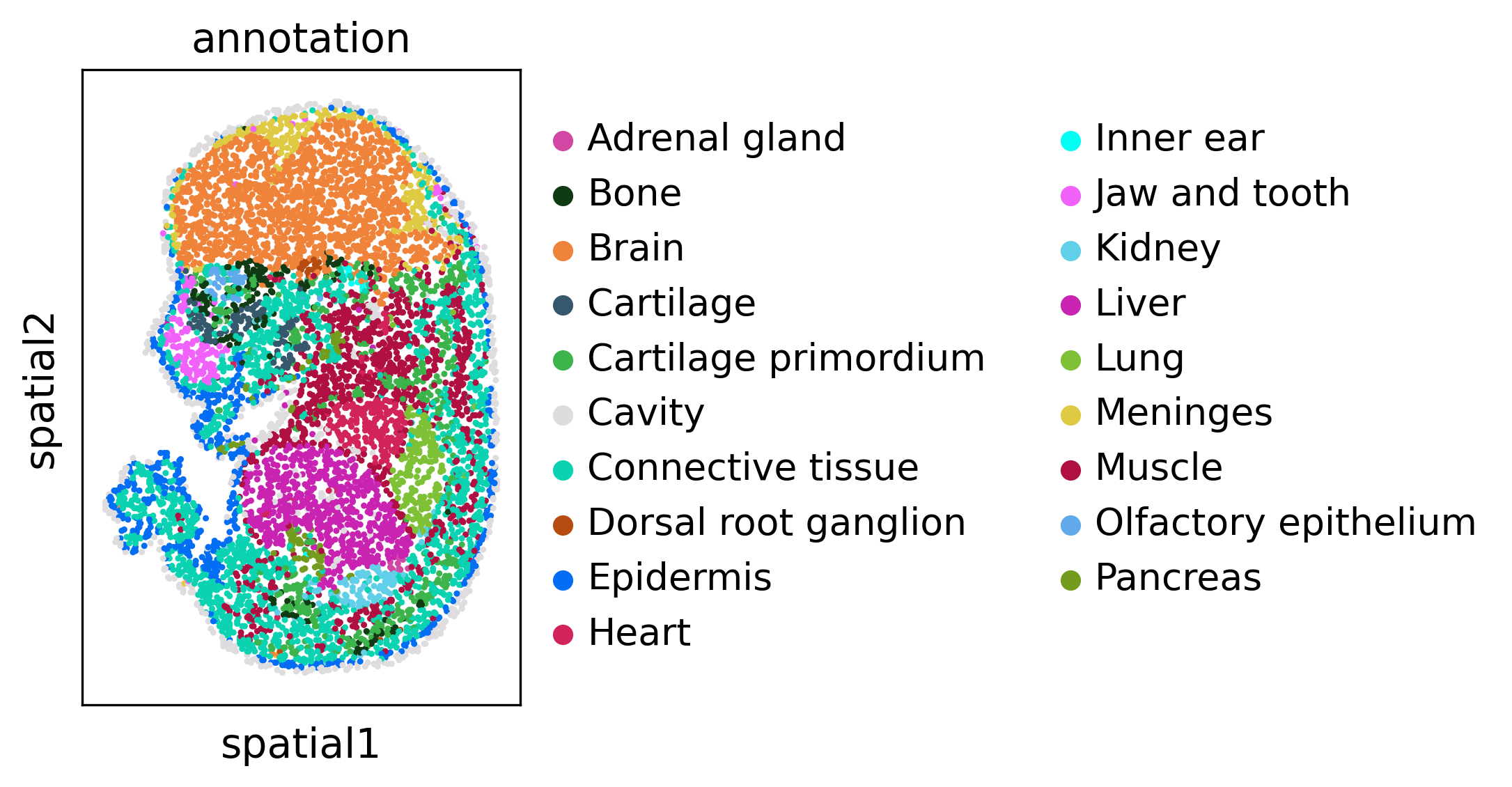
Run SLAT to align multi datasets simultaneously
SLAT has been optimized for for parallelism of multi-datasets alignment, all you need to do is arranging the datasets in correct order when running run_SLAT_multi function.
[7]:
start = time.time()
matching_list, zip_res = run_SLAT_multi([adata1,adata2,adata3,adata4], k_cutoff=10)
print(f'Use {time.time()-start:.2f} seconds')
Calculating spatial neighbor graph ...
Calculating spatial neighbor graph ...
The graph contains 90586 edges, 8000 cells.
11.32325 neighbors per cell on average.
The graph contains 90534 edges, 8000 cells.
11.31675 neighbors per cell on average.
Calculating spatial neighbor graph ...
The graph contains 90540 edges, 8000 cells.
11.3175 neighbors per cell on average.
Calculating spatial neighbor graph ...
The graph contains 90388 edges, 8000 cells.
11.2985 neighbors per cell on average.
Parallel mapping dataset:1 --- dataset:2
Parallel mapping dataset:2 --- dataset:3
Use DPCA feature to format graph
Use DPCA feature to format graph
Parallel mapping dataset:0 --- dataset:1
/rd2/user/xiacr/SLAT/conda/lib/python3.8/site-packages/anndata/_core/anndata.py:1785: FutureWarning: X.dtype being converted to np.float32 from float64. In the next version of anndata (0.9) conversion will not be automatic. Pass dtype explicitly to avoid this warning. Pass `AnnData(X, dtype=X.dtype, ...)` to get the future behavour.
[AnnData(sparse.csr_matrix(a.shape), obs=a.obs) for a in all_adatas],
/rd2/user/xiacr/SLAT/conda/lib/python3.8/site-packages/anndata/_core/anndata.py:1785: FutureWarning: X.dtype being converted to np.float32 from float64. In the next version of anndata (0.9) conversion will not be automatic. Pass dtype explicitly to avoid this warning. Pass `AnnData(X, dtype=X.dtype, ...)` to get the future behavour.
[AnnData(sparse.csr_matrix(a.shape), obs=a.obs) for a in all_adatas],
Use DPCA feature to format graph
/rd2/user/xiacr/SLAT/conda/lib/python3.8/site-packages/anndata/_core/anndata.py:1785: FutureWarning: X.dtype being converted to np.float32 from float64. In the next version of anndata (0.9) conversion will not be automatic. Pass dtype explicitly to avoid this warning. Pass `AnnData(X, dtype=X.dtype, ...)` to get the future behavour.
[AnnData(sparse.csr_matrix(a.shape), obs=a.obs) for a in all_adatas],
/rd2/user/xiacr/SLAT/conda/lib/python3.8/site-packages/scanpy/preprocessing/_normalization.py:170: UserWarning: Received a view of an AnnData. Making a copy.
view_to_actual(adata)
/rd2/user/xiacr/SLAT/conda/lib/python3.8/site-packages/scanpy/preprocessing/_normalization.py:170: FutureWarning: X.dtype being converted to np.float32 from float64. In the next version of anndata (0.9) conversion will not be automatic. Pass dtype explicitly to avoid this warning. Pass `AnnData(X, dtype=X.dtype, ...)` to get the future behavour.
view_to_actual(adata)
/rd2/user/xiacr/SLAT/conda/lib/python3.8/site-packages/scanpy/preprocessing/_simple.py:843: UserWarning: Received a view of an AnnData. Making a copy.
view_to_actual(adata)
/rd2/user/xiacr/SLAT/conda/lib/python3.8/site-packages/scanpy/preprocessing/_normalization.py:170: UserWarning: Received a view of an AnnData. Making a copy.
view_to_actual(adata)
/rd2/user/xiacr/SLAT/conda/lib/python3.8/site-packages/scanpy/preprocessing/_normalization.py:170: UserWarning: Received a view of an AnnData. Making a copy.
view_to_actual(adata)
/rd2/user/xiacr/SLAT/conda/lib/python3.8/site-packages/scanpy/preprocessing/_normalization.py:170: FutureWarning: X.dtype being converted to np.float32 from float64. In the next version of anndata (0.9) conversion will not be automatic. Pass dtype explicitly to avoid this warning. Pass `AnnData(X, dtype=X.dtype, ...)` to get the future behavour.
view_to_actual(adata)
/rd2/user/xiacr/SLAT/conda/lib/python3.8/site-packages/scanpy/preprocessing/_normalization.py:170: FutureWarning: X.dtype being converted to np.float32 from float64. In the next version of anndata (0.9) conversion will not be automatic. Pass dtype explicitly to avoid this warning. Pass `AnnData(X, dtype=X.dtype, ...)` to get the future behavour.
view_to_actual(adata)
/rd2/user/xiacr/SLAT/conda/lib/python3.8/site-packages/scanpy/preprocessing/_simple.py:843: UserWarning: Received a view of an AnnData. Making a copy.
view_to_actual(adata)
/rd2/user/xiacr/SLAT/conda/lib/python3.8/site-packages/scanpy/preprocessing/_simple.py:843: UserWarning: Received a view of an AnnData. Making a copy.
view_to_actual(adata)
/rd2/user/xiacr/SLAT/conda/lib/python3.8/site-packages/scanpy/preprocessing/_simple.py:843: UserWarning: Received a view of an AnnData. Making a copy.
view_to_actual(adata)
/rd2/user/xiacr/SLAT/conda/lib/python3.8/site-packages/scanpy/preprocessing/_simple.py:843: UserWarning: Received a view of an AnnData. Making a copy.
view_to_actual(adata)
/rd2/user/xiacr/SLAT/conda/lib/python3.8/site-packages/scanpy/preprocessing/_simple.py:843: UserWarning: Received a view of an AnnData. Making a copy.
view_to_actual(adata)
Warning! Dual PCA is using GPU, which may lead to OUT OF GPU MEMORY in big dataset!
Warning! Dual PCA is using GPU, which may lead to OUT OF GPU MEMORY in big dataset!
Warning! Dual PCA is using GPU, which may lead to OUT OF GPU MEMORY in big dataset!
Choose GPU:1 as device
Choose GPU:5 as device
Choose GPU:5 as device
Running
---------- epochs: 1 ----------
---------- epochs: 2 ----------
---------- epochs: 3 ----------
---------- epochs: 4 ----------
---------- epochs: 5 ----------
---------- epochs: 6 ----------
Training model time: 1.45
Running
---------- epochs: 1 ----------
Running
---------- epochs: 1 ----------
---------- epochs: 2 ----------
---------- epochs: 3 ----------
---------- epochs: 4 ----------
---------- epochs: 5 ----------
---------- epochs: 6 ----------
---------- epochs: 2 ----------
Training model time: 1.77
---------- epochs: 3 ----------
---------- epochs: 4 ----------
---------- epochs: 5 ----------
---------- epochs: 6 ----------
Training model time: 2.13
Use 27.86 seconds
[8]:
index_list = [i[1] for i in zip_res]
index_list[2].shape
[8]:
(8000, 20)
Then we build 3D model based on the aligned datasets
[9]:
model = build_3D([adata1,adata2,adata3,adata4], matching_list)
model.draw_3D(hide_axis=True, line_color='red', height=10, size=[8,20], line_width=1)
Mapping 0th layer
Mapping 1th layer
Mapping 2th layer
